Artificial Intelligence
If you are new to Artificial Intelligence and machine learning, there is one place to go: the machine learning glossary from the Google developers documentation.
For the complete bibliography, please look at the bibliography file.
Train yourself 🤓
- Best Deep Learning Courses: Updated for 2019
- Best Deep Learning Books: Updated for 2019
- A Visual Exploration of Gaussian Processes - Discovering or rediscovering Gaussian Processes in an interactive fashion.
- A Comprehensive Introduction to Different Types of Convolutions in Deep Learning - A comprehensive guide to convolutions.
Embedding 🎹
-
FaceNet: A Unified Embedding for Face Recognition and Clustering - A solution which transforms an image into a compact Euclidean space allowing to enhance Face Recognition.
implementation (
Embedding,image2vec,Tensorflow) -
Grasp2Vec: Learning Object Representations from Self-Supervised Grasping - Embedding used in reinforcement learning to represent reality through physical world robot grasping.
Google article (
Embedding,image2vec,RL)
Natural Language Processing and voice recognition 🗣
- Assisted writings
- “I want to live” - A 60 second clip entirely scripted from an AI studying 15 years of worth of award-winning ads.
- Bertie the Forbes’ CMS - Forbes announced its new AI powered CMS (Content Management System) where AI helps and support content creator from image selection to draft article writings.
-
Accurate Online Speaker Diarization with supervised learning - Detect interlaced speakers in a speech. But beware, code is not the original and you cannot access data. (
PyTorch,Embedding)
Semantic segmentation ✏️
Semantic segmentation is the practice of categorizing an image at the pixel level. i.e., semantic segmentation assigns a class to each pixel in an image. Semantic segmentation was at the heart of our core products at Redbird. There are a lot activities around that topic where state of the art is still not as accurate as human. I have written a medium post where you will find further information regarding our projects.
Here are the most relevant findings we leverage for our project and some more recent ones that can enhance it:
- Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation - The next DeepLab generation which was already the state of the art in this field.
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics - Multi-task learning for segmentation and instance segmentation with a multi-task loss.
- Panoptic Feature Pyramid Networks - Unified architecture for multi task segmentation and instance segmentation.
Datasets 💽
- AWS OpenData
- Adding Diversity to Images with Open Images Extended
- BigQuery Datasets
- Datasetlist
- Kaggle Datasets
- Open Images Dataset V4
- UCI Machine Learning repository
Data annotation 📝
- List of manual image annotation tools - The list of annotation tools is long, unfortunately the Wikipedia rule enforce certain criteria I think are not smooth enough to enable tool discovery in fast pace changing environments. In that case, please take a look at the talk page of this article, there is pletoria of tools to discover here.
- Polygon-RNN:
- Curve-GCN:
- Fast Interactive Object Annotation with Curve-GCN - Graph Convolutional Network (GCN) leveraged to speedup manual objects annotation. Trained on Cityscape, yet generalized on other data types such as Aerial or Medicine. Advertised to be 10 to 100 times faster that polygon-RNN.
- “Code” - You need to signup to get an access to the code!
- Video
- doccano - Open source text annotation tool
- A Guide to Learning with Limited Labeled Data - This overview guide to active learning comes with a neat and inspiring prototype.
Annotation (as a) services:
- supervise.ly - Is a an online service that enable automatic annotation of data. Fron the tens I tested it is my current favorite.
- Alegion - Annotation service that deals with computer vision, NLP, and data cleansing. The service alleges to combine machine learning and Human intelligence.
- Scale.ai - With a “simple” API to programmaticaly request Human annotation from their service, Scale.ai aims to free projects from the annotation task.
- Super Annotate - Seems to leverage both AI and superpixels to support the annotation process.
Data Generation 🖌
Face and ImageNet generation 🎭
- Inside the world of AI that forges beautiful art and terrifying deepfakes - A 2018 overview of GAN and latests progress in the field of generative networks.
- A Style-Based Generator Architecture for Generative Adversarial Networks - Here we are, on December 2018 we discovered than a computer can generate images that we can definitely take for real ones. summary.
- High-Fidelity Image Generation With Fewer Labels - This paper proposes a solution to achieve state of the art GAN performance on ImageNet with 10% of the labels. Blog announcement
Scenes generation 🌄
- AI software can dream up an entire digital world from a simple sketch - A photorealistic 3D engine renderer made out of GAN.
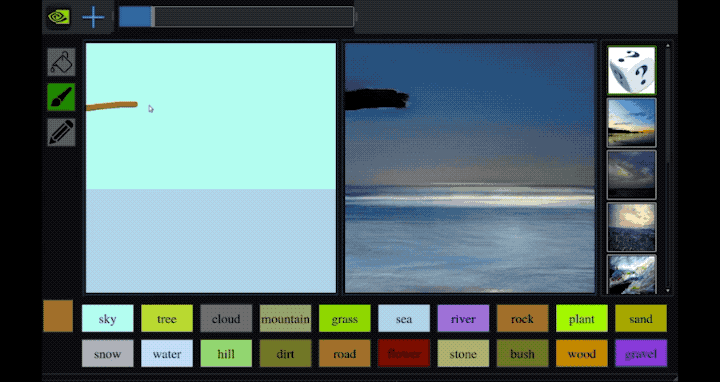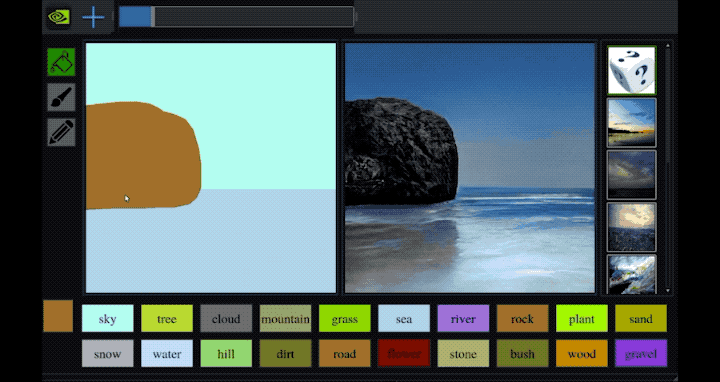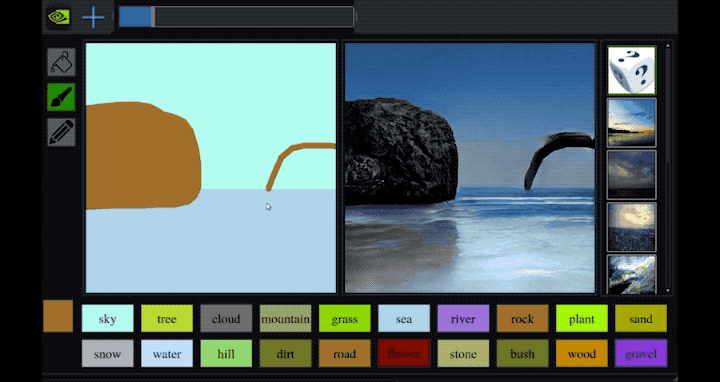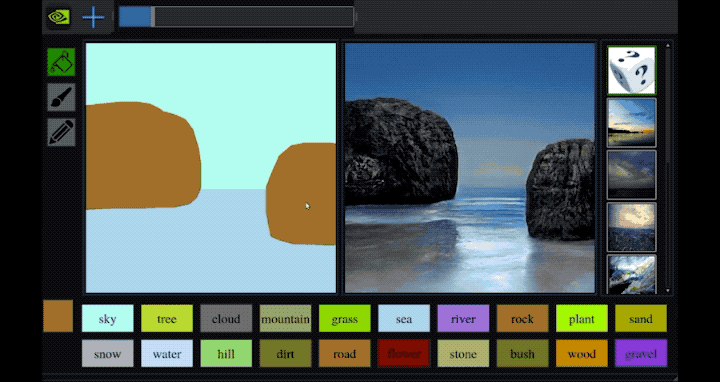
- GauGAN Turns Doodles into Stunning, Photorealistic Landscapes - This NVIDIA last sketch to photo GAN network based application - named GauGAN - results are unbelievable. repository, paper
Object generation 🕸
- Visual Object Networks: Image Generation with Disentangled 3D Representation - How a set of specialized networks learn to generate 3D objects.
- This is the most complex generative design ever made - Purely inspirational, no implementation design, still further details are accessible here.
Understanding the black box ◼️
One of the main challenges we face when we interact with artificial intelligence projects is to reproduce results, understand how they work, and explain decisions. Neural networks are known as black boxes, famously known for being impenetrable.
The European Union’s General Data Protection Regulation (GDPR) which is designed to ensure and to strengthen data security and privacy of all 28 EU members states’ citizen including data held outside of the EU either the data is related to employees or customers includes rights to explanation 1, 2:
- Article 22: Grants citizens “the right not to be subject to a decision based solely on automated processing” that “significantly affects him or her.”
- Recital 71: The data subject should have “the right… to obtain an explanation of the decision reached… and to challenge the decision.”
- Article 13: The data controller must provide the subject, at the time his or her personal data is obtained, with “meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing” for the subject.
- Article 15: Subjects have a right to know what personal data a company is using and how it’s being used.
With that in mind, most businesses claiming to use AI or using AI without declaring it then have a complicated puzzle to solve. They must be able to explain any algorithm driven decision implying a Human.
We are seeing more and more attempts to understand and interpret them, to unpack their choices, to reproduce experiments, and to debug them.
You must be careful with whoever tells he can surely explain how a deep learning model takes a decision. Still a cutting edge research topic.
- A New Approach to Understanding How Machines Think - An interview of Been Kim from Google Brain for the introduction of “Testing with Concept Activation Vectors” TCAV
- A neural network can learn to organize the world it sees into concepts—just like we do - In this paper, GAN are examined under a microscope, it is a major leap forward into comprehension of GANs.
- Exploring Neural Networks with Activation Atlases - Feature inversion support an activation atlas of features the network has learned. And you can play with it! Blog announcement.
- Four Experiments in Handwriting with a Neural Network - Interactive experiments to understand network based on your handwriting inputs
- ICLR Reproducibility Challenge - A challenge that encourage people to try reproducing a paper from the 2019 ICLR submissions. The goal is to assess that the experiments are reproducible.
- Machine Learning for Kids - If you want my mind, it is valuable not only for kids 😅
- The Building Blocks of Interpretability - A reproducible paper that combines different technics in order to better understand networks.
- The Machine Learning Reproducibility Checklist - It is so hard to reproduce today’s publication that some initiatives like this reproducibility checklist arise and provide rules to follow.
- awesome-machine-learning-interpretability - Another awesome list dedicated to machine learning interpretability, it wants itself to be an incomplete, imperfect blueprint for a more human-centered, lower-risk machine learning.
- comet.ml - An online platform compatible with any Machine Learning framework that aggregate online stats and enable model comparison.
-
distill.pub - This is an attempt to modernize the main issues we face with the traditional printed scientific papers in computer science and machine learning which now more than ever involve an overabundant amount of data and are nearly impossible to understand on a sheet of paper. Distill.pub brings clarity, reproducibility, and interactivity.
PDFfiles are from another age.distill.pubis an expression of our time. - manifold - A platform from uber that promises ease of debugging, not publicly shared, not available for test, pretty, and a lot of ideas still.
Performance and hardware 🏎
- A full hardware guide to Deep Learning - If you want to build your own local hardware for training, this is a must read.
- Best Deals in Deep Learning Cloud Providers - Where does it more effective to train your models. AWS is the most expensive.
- GPipe introduction - From Mini- to Micro-Batches, GPipe partitions a model (Model parallelism) across different accelerators to efficiently train large-scale neural network models.
Ethics 👴🏻
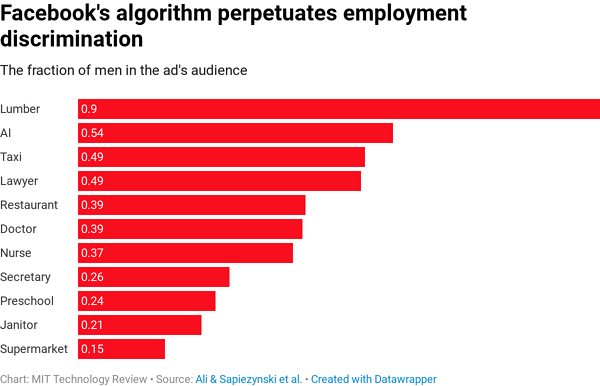
All algorithms are biased; Facebook’s is no exception.
United States of America Department of Housing and Urban Development sued Facebook on the 28th of March 2019. The HUD alleged that the paying Facebook ads service let advertisers purposefully target their ads based on race, color, religion, sex, familial status, national origin or disability.
This is the tip of the iceberg; bias can be found in a lot of places in artificial intelligence projects. The following is a result of a set of celebration images.

A “simple” analysis of the ImageNet images origin gives clues on the bias reasons.
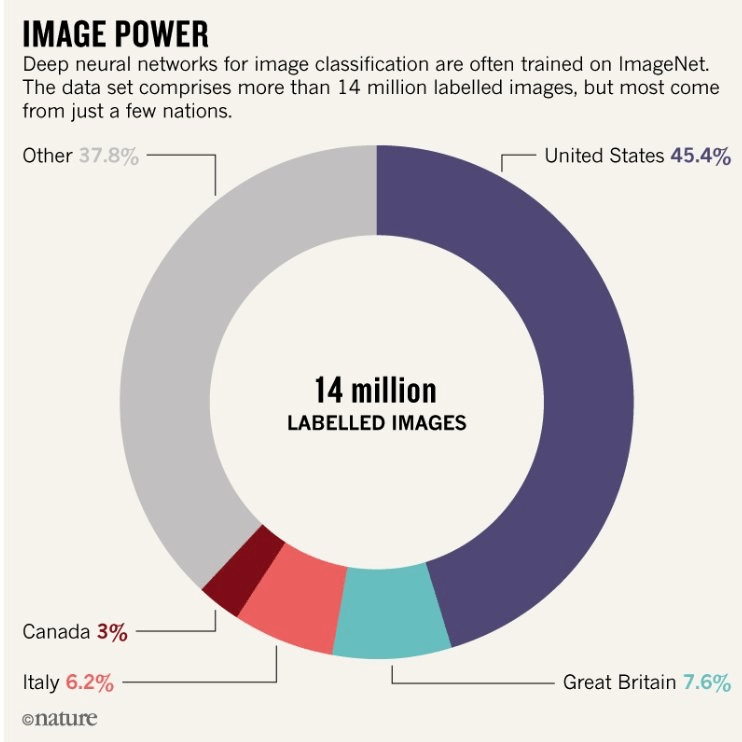
This paragraph focuses on fact analysis and key initiatives.
-
7 essentials for achieving trustworthy AI - The seven ethics principles from the European Commission regargind Artificial Intelligence development. “Trustworthy AI should respect all applicable laws and regulations, as well as a series of requirements”:
- Human agency and oversight: AI systems should enable equitable societies by supporting human agency (ed: the capacity to act independently and to make their own free choices) and fundamental rights, and not decrease, limit or misguide human autonomy.
- Robustness and safety: Trustworthy AI requires algorithms to be secure, reliable and robust enough to deal with errors or inconsistencies during all life cycle phases of AI systems.
- Privacy and data governance: Citizens should have full control over their own data, while data concerning them will not be used to harm or discriminate against them.
- Transparency: The traceability of AI systems should be ensured.
- Diversity, non-discrimination and fairness: AI systems should consider the whole range of human abilities, skills and requirements, and ensure accessibility.
- Societal and environmental well-being: AI systems should be used to enhance positive social change and enhance sustainability and ecological responsibility.
- Accountability: Mechanisms should be put in place to ensure responsibility and accountability for AI systems and their outcomes.
- AI Safety Needs Social Scientists - An extensive explanation towards the Social Scientists requirement explanation.
- Advanced Technology External Advisory Council (ATEAC) - The idea was that a team made of philosophers, engineers, and policy experts would have regulated Google’s AI projects based on AI principles. The controversy raised by this initiative was so high than in less than a month the initiative has been canceled. Actually, 1720 Google employees have signed a petition asking the company to remove Kay Cole James, the president of the conservative Heritage Foundation, from the panel. Despite all that noise, I see here a trend and a light on a growing issue with artificial intelligence projects and their potential impacts on real lives.
- China’s top AI scientist drives development of ethical guidelines - Yes it is time for the world to align itself on where it wants to go
- Counteroffensive against GPT-2 - Perpetuating the long tradition of cat and mouse play, a new AI developed by researchers at MIT, IBM’s Watson A.I. Lab and Harvard University has been built to detect text generated by AI and therefore providing a tool to fight fake news! It comes with a nice demo
- GPT-2 blog post announcement - OpenAI released a blog post along their paper Language Models are Unsupervised Multitask Learners explaining why they won’t share reproducibility parameters (regarding data and hyperparameters notably). The GPT-2 performances are unbelievable and in the absence of clear ethics in the artificial intelligence field I can’t agree more at that time. Nevertheless, I’m utterly frustrated. We need to do something about the social implications of artificial intelligence. In the OpenAI’s GPT-2: the model, the hype, and the controversy blog post, the idea of a ‘safety checklist’; similarly to the recent ‘ reproducibility checklist’ arises. Why not?!
- Google is trying to remove gender bias from its translation services - Gender bias is one of the problem in engineering, mostly only male all around. It is so easy to implement those bias and transmit them to the machine.
- Research priorities for robust and beneficial Artificial Intelligence - The first round of people who expressed worries in the current research state of AI. It should be directed toward beneficial outcomes: “our AI systems must do what we want them to do”.
- Thinking inside the box: using and controlling an Oracle AI - Controlling AI has been a problem for a while even before the rise of deep learning. In this paper, you’ll discover that a particular topic can raise a lot of questions, even if it seems simple at first: here controlling an Oracle AI that doesn’t act in the world except by answering questions.
Supporting Technology 👩🏼🔧
In our experience, Keras and Ternsorflow served us well, allowing us to reach our targets within the boundaries of our budget. For some others, it might be pyTorch and FastAI. The current landscape is evolving fast, and some new players or languages are entering the game.
In any case, please do not move to another framework just because “it is better”. One more time, all the time you spend should be devoted to business value creation, not dogmatism. You should move to another framework if and only if it serves a purpose and you are carefully making that decision.
Sagemaker 🤖
sagemaker is quickly becoming a state of the art for machine learning project. It assembles under this sole name a lot of capabilities that would accelerate and standardize any launching project involving machine learning of any sort. From
collaboration to
continuous deployment of model, through
ground truth generation sagemaker provides all necessary tools for most of the use cases.
The initial version of sagemaker has been released on
Nov 29, 2017. As we were working on machine learning projects applied to production in early 2016, we needed to figured out by ourselves and our small team how to build, train and deploy our custom models. Spending a consequent amount of time in setting the instances, installing latest version - available at that time - of cuda and tensorflow and connecting the dots in the process.
If I would start something new today, sagemaker would be my primary target as a CTO, helping my future team to focus on the value added, not the infrastructure and process on which everyone - starting with AWS - is working on.
A sagemaker workflow for continuous deployment ©
AWS:
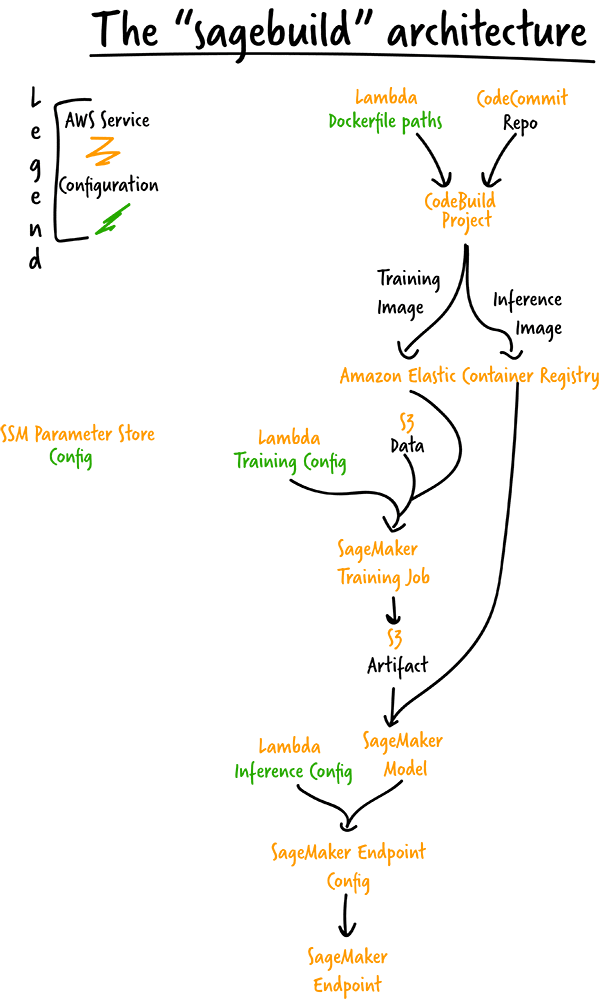
sagemaker use cases demonstration:
other sagemaker key features:
-
Pipe mode - It allows to stream data directly from an
S3bucket without the need to download the data on the machine. It leverages the protobuf to speedup streaming from S3 to the training instances.
Tensorflow
Setting an AI project 📈
Executing an enterprise grade artificial intelligence project is complicated, a lot of steps are necessary in a highly uncertain context. As of today, you have a lot of choices to set your projects right. Depending on your team size, you might even willing to reinvent the wheel suffering from the “Not Invented Here” syndrome. The good news is there is a lot to learn from the already maturing industry.
In its Machine Learning Maturity Model IBM presents a set of best practices to implement when a company wants to deploy artificial intelligence projects at scale and in a friendly fashion with enterprise landscape. Many of those best practices might be too complicated to achieve, anyhow, it will highlight any shortcomings in your projects and potential area of focus.
The following are some thoughts on different aspects of an artificial intelligence project.
Defining the system’s purpose 🎯
When it come to artificial intelligence project definition I see two main purpose:
- The business outcome: either we will automate manual activity or we will create new value,
- The technical results of your project.
Building safe artificial intelligence describes the nascent field of technical AI safety and propose a framework to model and understand AI system. This is the second aspect.
The team 🎳
The How to build a machine learning team when you are not google or facebook article highlights best practices that a good manager will discover himself executing an artificial intelligence project. Pragmatism has always been at the heart of our strategy including went it came to our artificial intelligence projects. I always prefered to leverage in place resources. And there is one thing for sure: as of today, “it’s more efficient to teach a engineers machine learning than to teach machine learning practitioners how to be good engineers.” With the right project and the rock solid computer scientists you can kick-start an artificial intelligence project with a small team.
If you are an equivalent to Google or Facebook 😄 - written otherwise, you have the means to set a large team and set different roles, and responsibilities - here are twelve functions which operate on Artificial Intelligence projects. It is meant to give a taste of the variety of responsibilities. The below listing is an adaptation of the article mentioned above.
- Data Engineer: responsible for data delivery to the rest of the team. From a spreadsheet to big data engineer (block storage management, database, data lake, etc.)
- Analyst: responsible for the first set of data analysis, familiar with more advanced tools than the spreadsheet like R or programmatic data viz.
- Expert Analyst: responsible for the same tasks than the analyst at a higher speed. Faster, stronger.
- Statistician: responsible for preventing others from concluding too quickly at the end of every day.
- Applied Machine Learning Engineer: responsible for leveraging on the shelf algorithms, connecting them to your data.
- Data Scientist: responsible for all above roles except decision making.
- Qualitative Expert / Social Scientist: responsible for setting the right KPI and metrics understood by all the stakeholders.
- Researcher: responsible for solving your issues if the project is in its last resort and that you have exhausted all industry options.
- Domain expert: responsible for providing the best insight on the industry you are working, data definition, business rules, scenarios, etc.
- UX designer: responsible for getting the most out of your project putting the model into action and crafting end users interactions with it.
- Ethicist: responsible for checking the validity of your project according to a set of predetermined rules (several are available more in to come on this topic in the current page); from diversity to explainability, etc.
- Analytics Manager / Data Science Leader / Decision-Maker: responsible for team orchestration, getting the most of everyone and the data. This implies strong decision making accounting for the potential impact on business. A wide topic that heavily depends on data nature and team members. I assured that role at Airware.
Several of these roles are detailed or approached from other angles in this documentation.
From craftsmanship to engineering 🏗
Productionizing an artificial intelligence project, tracking its progress or solely being able to reproduce an experiment is a challenge. We see traditional computing systems as deterministic: for a particular version of your code, you get specific behavior. You can upgrade your software or dependencies to a specific version to benefit some improvements or you can roll-back to a previous version of it if you face some unexpected issues. Infrastructure as code paradigm enables the same features for the underlying elements supporting your project.
For years now, continuous delivery is a well-known concept, often applied in production.
When it comes to artificial intelligence projects it is steadily way more tricky: how do you manage that so-called black box? The good news is that the black box can also be versioned. You can version an artificial intelligence project on different axes: code, model, data schema, data values, and data annotations. There is not only one approach, and it can become highly complex. It depends on your project ambition, data variation, number of people involved, go-live frequencies, etc. You must find the most appropriate way for each project. In my experience, versioning models, associated code and data annotations have proven to be the bare minimum - and even it wasn’t always sufficient to reproduce a particular experiment. Some tools or services that might assist you in this mission:
Another divergence from traditional computer science problems is testing and debugging. During the past 70 years, computer science engineers have established strategies and best practices for testing, debugging and ensuring code quality before deployments. The toolkit is impressive: unit tests, integration test, test driven development, performance verification, human acceptance tests, etc. Those practices are not directly applicable nor always suitable for modern artificial intelligence projects. How to formally test a network of millions of parameters? The current de facto method is to split your training database intelligently in a train set and a test set - We used to apply genetic programming to get the most of this split at Airware. But this often doesn’t ensure production high performance nor robustness and doesn’t verify that your models are bulletproof to worst cases or worse to hacking.
Some Tencent engineers “simply” used little stickers to force the “in production” Tesla’s autopilot to change lane: from the right one to the wrong one. With autonomous vehicles, it would be disastrous. With medicine, financial, insurance or retail the consequences could be just as unfortunate or painful. The article “You created a machine learning application. Now make sure it’s secure." explains all known hacking technics a model can suffer from.
The following example illustrates how changing imperceptively an image can trick a model into identifying a “Sloth” as a “Racecar” with >99% confidence. And, it gives an idea of how weak networks can be.

This is called an adversarial example: inputs to a neural network resulting in incorrect outputs. Explaining and Harnessing Adversarial Examples will provide you all technical details. How to trick a neural network into thinking a panda is a vulture will give you technical information to reproduce the experiment yourself. This article will provide you with yet another taste.
In Towards Robust and Verified AI Deepmind states that machine learning systems are not robust by default and exposes three approaches for rigorously identifying and eliminating bugs in learned models to achieve Machine Learning robustness. These three approaches are directed toward ensuring that the produced system complies with its specifications.
- Adversarial testing: the idea is to leverage adversarial strategies to systematize and harnessing testing over random approaches, searching for the worst case outcome. Given example illustrates that surprisingly simple adversarial example can lead to failure.
- Robust learning: the idea is to build networks that are agnostic to adversarial testing changing the learning algorithms.
- Formal verification: the idea is to provably demonstrate that models’ predictions are consistent with a specification for all possible inputs bounding the outputs of the network.
These three approaches are in their early stage. I expect a lot more to come.
Conclusions
- Don’t reinvent the wheel, just like all other computer science project!
- Don’t be afraid to get your hands dirty, if you are working on cutting edge projects, your data won’t be annotated. Obviously you can outsource annotation, but one need to understand what it means.
- Be humble, the research is going really blasting fast.
- Accept failure, and be patient. Only one thing is sure, in any machine learning project you’ll met failure. Reaching success might be a long way…
Further inspiration 💡
- Robust Website Fingerprinting Through the Cache Occupancy Channel - What if you can leverage machine learning and a Javascript security hole to track anyone browsing history?
- Track the number of coffees consumed using AWS DeepLens - How to build a coffee tracker in the open space with AWS deeplens.
- Deep Learning State of the Art (2019) - MIT - A lecture from @lexfridman on recent developments in deep learning. That is a very good overview of 2018 state of the art in research and applied deep learning.
- Koniku - This company builds co-processors made of biological neurons.
As we are loosing most of the nonverbal communications in a large portion of our day to day modern human to human interactions, I’ve always been curious on how we could extend it with expressive enhancements that would explain much more than lengthy descriptions. “A picture worths a thousand words.” Some attempts:
- Dango - Is an application and API to propose relevant emojis and GIFs based on your text input in messaging. This unfortunately doesn’t provide the code.
- live-mood - A former team member worked on a twitch extension to continuously transcribe watchers mood on a stream.
Agriculture 🌱
- Machine learning is making pesto even more delicious - How machine learning was used to develop a surrogate model of Basil and provide new counter intuitive recipes. Source paper
Augmented reality 👓
- Real-Time AR Self-Expression with Machine Learning - Impressive on device real time AR applied on faces. Two networks work jointly to first detect the face on the stream and second to generate the Mesh.

Compression, enhancement 🗜
- Learned Video Compression - A traditional codec architecture where elements are replaced by Machine Learning ones. Results: the new codec outperforms all existing video codecs.
Energy management 🔋
- EnergyVault - The cleverest idea ever regarding energy storage. Thinking out of the box is key when you are growing a startup. Here is the perfect example.
- Tibber - Norway and Sweden based startup helps you “smartly buy electricity at the best price at the right time of the day every day”.
Experiments & Art 🎨
On October 2018, an ink-on-canvas portrait created using artificial intelligence was sold at Christie’s New York. The first AI-generated artwork to be offered by a major auction house. The estimate was $7,000-$10,000. It went for $432,500.

The 1917 “Fountain” from Marcel Duchamp, a porcelain urinal signed “R. Mutt” arranged as a piece of art is world famous. In 1999, a replica of Marcel Duchamp’s original Fountain was purchased by Dimitri Daskalopoulos, a Greek collector, for 1.76 million dollars. I’m not a philosopher. I’m not an artist. I can’t say what Art is. The sole fact some are discussing it is the sign that Artificial intelligence generated pieces might be art. Earth, everyday furniture, paint, pen, pencil, coffee, Lego, computers painting, and now artificial intelligence are to me medium to produce pieces of art: pieces that tell you something about yourself.
- Music:
- Semi-Conductor - A Google AI experiment that allow one to conduct an orchestra from the browser
- Painting:
- amalGAN - Alexander Reben used brain waves, GAN network and side supportive networks to generate a set of visually unusual paintings that are physically reproduced in a Chinese town: a human-machine global collaboration.
- Spotting AI-generated faces:
- nikola MIT experiment - People at MIT had set an online test that asks you to spot generated faces with NVIDIA’s Progressive GAN. I tried it myself and wasn’t 100% correct 😅. Some
- How to recognize fake AI-generated images - An extensive look into AI-generated images that will train yourself to spot fake images.
- Future is brilliant
- Neural Ordinary Differential Equations - Explorative new family of neural network that “parameterizes the derivative of the hidden state using a neural network”.
- Relational inductive biases, deep learning, and graph networks - Advocacy for combinatory between “hand-engineering” and “end-to-end” learning in order to overcome current full deep learning approachs.
- AICAN HG Contemporary February exhibit - Faceless Portrait #5 is Terminator as an art piece. Someone will see a disturbed AI
Games 👾
- Starcraft AI competition - The state of the Starcraft competition. Samsung 1st, Facebook 2nd.
-
Mortal Kombat - A
Tensorflow.jsproject that allows you to play Mortal Kombat with your webcam. - TensorKart - Game played with an Xbox became training data for an off the shelf model to train an agent playing MarioKart 64. Data are all around us!
Medicine 👩🏽⚕️
- AI Is Good (Perhaps Too Good) at Predicting Who Will Die Prematurely - A deep learning model trained on genetic, physical and health data submitted by more than 500,000 people between 2006 and 2016 has been able to be “significantly more accurate” than all previous models; it has been able to correctly identify 76 percent of subjects who died prematurely during the study period.
- Artificial Intelligence Can Detect Alzheimer’s Disease in Brain Scans Six Years Before a Diagnosis - It is not a question of time any more, it is already here.
- Brain2Speech - Experiment using AI to get our voice out of our head automatically. The promise to an accessible world for disable people.
- Detection of patient mobilization activities in the ICU - How a deep learning based computer vision can help to monitor patient mobilization and to mitigate risk for post-intensive care syndrome and long-term functional impairment in intensive care unit (ICU).
- Face2Gene - From Professional crowdsourcing to real life medicine aid use case, the face2gene application that spot genetic disorders is a promise for future medicine.
- Learning to Design RNA - Reinforcement Learning used to design RNA sequence to test
Natural Language Processing (NLP)
- Ten trends in Deep learning NLP - 10 trends for 2019 on NLP. Discove BERT, ELMO, Embedding, Transformers and predictions for 2019
- Lithium-Ion Batteries - Lithium-Ion Batteries is a machine generated summury of current research in Lithium-Ion Batteries; an impressive result of NLP algorithm. Press release
Online AI experiments 🔬
- Iconary - Iconary from researchers at the Allen Institute for #AI is an online drawing and guessing game based on Pictionary. Its engine #AllenAI will blow your mind.
- AI Experiments - Curated list of AI experiments from Google. Doodle guessing, AI assisted drawing, Music, etc.
- NVIDIA playground - Recent AI research available as online playgrounds. “Under construction”
- Active Learning - Active Learner Prototype that illustrates learning with limited labeled data
Physics and astronomy 👩🏻🔬
- AI helped discovering two new planets Deep learning - more precisely a convolutional neural network - helped astronomers at the University of Texas in Austin, NASA and Google Brain searchers to predict whether a given possible exoplanet signal is a true exoplanet or a false positive. Result: two new planets, K2-293b and K2-294b, orbit stars in the constellation Aquarius, 1,300 light years away. Original Paper
Robotics 🤖
- kPAM: KeyPoint Affordances for Category-Level Robotic Manipulation - How defining a semantic 3D keypoints as the object representation help drastically reduce need for data during training phase to teach a robot arm to move objects. Video Demonstration.